The Challenge
Sales teams often face a high volume of inbound leads, but not all leads are created equal. Manually filtering through them is time-consuming and often leads to “sales fatigue” and missed opportunities. The goal was to build a system that automatically ranks leads based on their likelihood to convert, allowing the sales team to focus their energy where it matters most.
The Solution
I developed an end-to-end Machine Learning pipeline to predict lead conversion (binary classification).
- Data Engineering: Cleaned and preprocessed customer behavioral data, handling missing values and categorical encoding.
- Feature Engineering: Extracted insights from lead origins, website activity, and engagement metrics to create predictive features.
- Model Development: Evaluated several classification algorithms (Logistic Regression, Random Forest, and XGBoost) to find the best balance between precision and recall.
- Optimization: Focused on minimizing “False Positives” to ensure the sales team doesn’t waste time on cold leads.
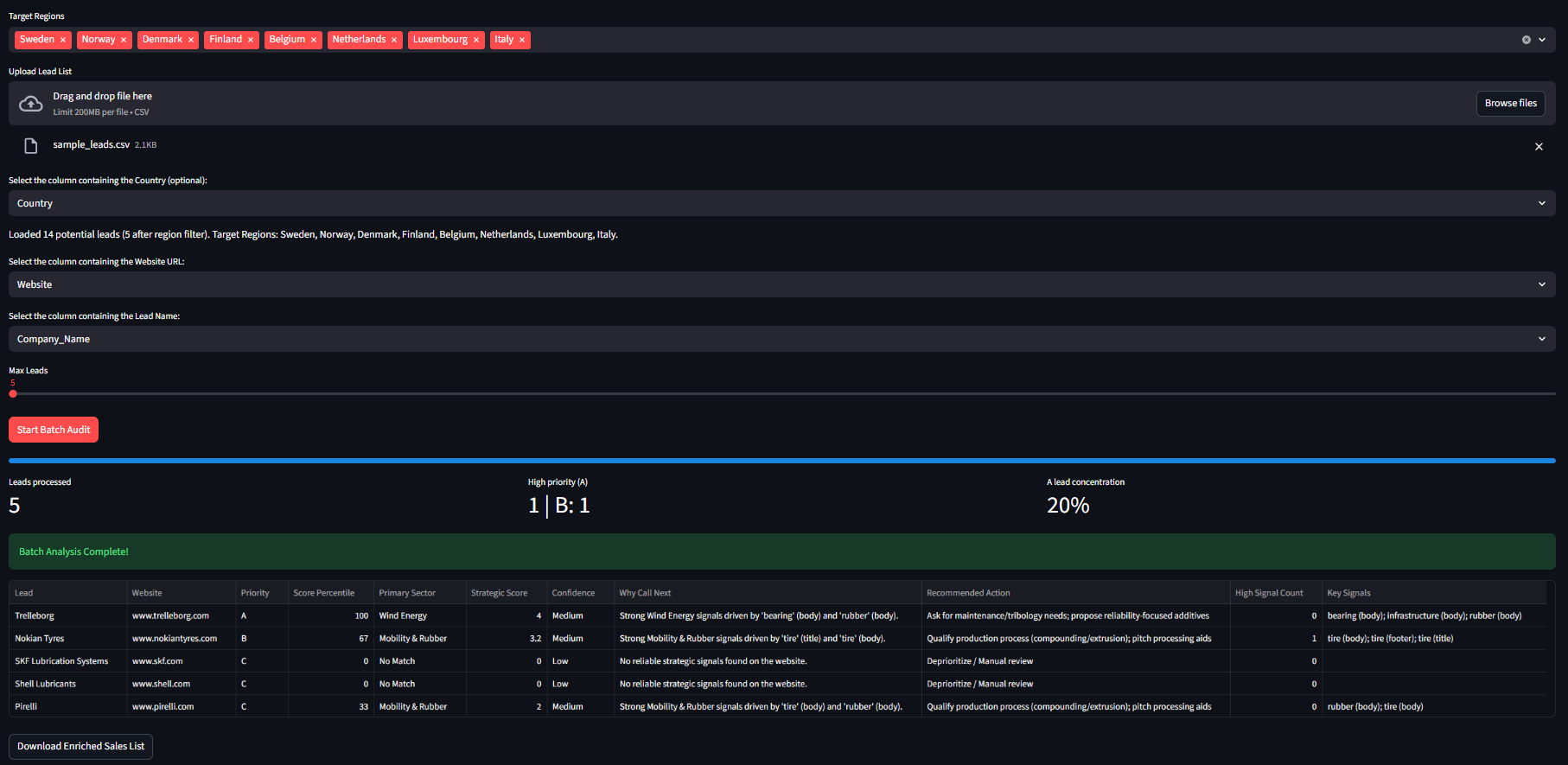
A look at the final interface: The dashboard shows real-time processing, lead concentration metrics, and a detailed breakdown of strategic signals for each prospect.
Key Results
- Prioritization: The model successfully identified the top 20% of leads that accounted for over 80% of potential conversions.
- Actionable Insights: Discovered that specific engagement triggers (e.g., time spent on the pricing page) were stronger predictors than traditional demographic data.
- Performance: Achieved a high AUC-ROC score, demonstrating robust discriminatory power between converting and non-converting leads.
Tech Stack
- Languages: Python
- Libraries: Pandas, NumPy, Scikit-Learn, Matplotlib/Seaborn
- Algorithms: Random Forest, XGBoost, Logistic Regression
- Workflow: Jupyter Notebooks, Git
Try the Tool
You can upload a sample CSV or download one here.